icode使用的字符分割算法源于sourceforge上一个叫Java OCR的开源项目,经测试发现该算法不适用于字符有粘连的情况。
该算法的最终目的是将图像进行二值化编码。比如:
0=
00000000000000000000
00000000111100000000
00000011111111000000
00000111100111100000
00000111000001100000
00001110000001110000
00001110000001110000
00011100000001110000
00011100000001110000
00011100000001110000
00011100000001110000
00011100000001110000
00011100000011110000
00011100000011110000
00011100000111000000
00011110001111000000
00000111111110000000
00000011111000000000
00000000000000000000
00000000000000000000
要想使图像易于二值编码,前期的图像处理至关重要。处理的目的就是要尽可能地保留有用信息和去除干扰。 下面就几种常见的干扰类型来说明处理方案:
图像有噪点,如噪点图片![]() 。如果噪点颗粒相比于字符点迹像素颗粒较小,那么可以采用本项目中package com.icode.ocr下的OcrFilter类中的median(中值滤波)系列方法来处理这类噪点。目前可用的median系列方法有两个:medianX(X方向中值滤波)和medianY(Y方向中值滤波),窗口大小固定为3(medianX为横向相连三个像素,medianY为纵向相连三个像素)。
。如果噪点颗粒相比于字符点迹像素颗粒较小,那么可以采用本项目中package com.icode.ocr下的OcrFilter类中的median(中值滤波)系列方法来处理这类噪点。目前可用的median系列方法有两个:medianX(X方向中值滤波)和medianY(Y方向中值滤波),窗口大小固定为3(medianX为横向相连三个像素,medianY为纵向相连三个像素)。
JAVA代码:
public static void main(String[] args) throws IOException {
BufferedImage image = ImageIOHelper.getImage(new File(target4));
JFrame frame = new JFrame();
frame.setLayout(new FlowLayout());
frame.setBounds(480, 240, 900, 600);
JLabel label = new JLabel("(OcrFilter处理前)",new ImageIcon(image), 0);
frame.add(label);
image = new OcrFilter(image).medianX().medianY().optBufferedImage();
JLabel label2 = new JLabel("(OcrFilter处理后)",new ImageIcon(image), 0);
frame.add(label2);
frame.setVisible(true);
}
}
实测该参数下能较好地滤除小颗粒较零散的噪点,效果如图:
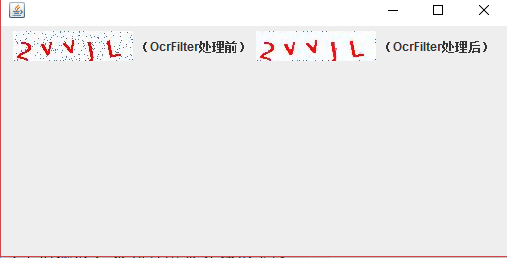
中值滤波后图像将变得更清晰,但是颜色还是比较浑浊。接下来为了增强颜色,我们使用单门限二值化来进行处理:
public static void main(String[] args) throws IOException {
BufferedImage image = ImageIOHelper.getImage(new File(target4));
JFrame frame = new JFrame();
frame.setLayout(new FlowLayout());
frame.setBounds(480, 240, 900, 600);
JLabel label = new JLabel("(OcrFilter处理前)",new ImageIcon(image), 0);
frame.add(label);
//手动确定阈值:100
image = new OcrFilter(image).medianX().medianY().extrem(100).optBufferedImage();
JLabel label2 = new JLabel("(OcrFilter处理后)",new ImageIcon(image), 0);
frame.add(label2);
frame.setVisible(true);
}
}
处理后效果如图:
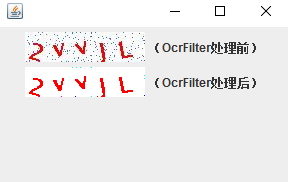
单门限二值化
是不是感觉图像越来越完美了^_^?但是仔细看会发现图像边缘仍有部分噪点,这是前面的中值滤波遗留下来的。不过没关系,二值化后字符的主要构成颜色(RGB=(255,0,0))已经完全显现出来了:
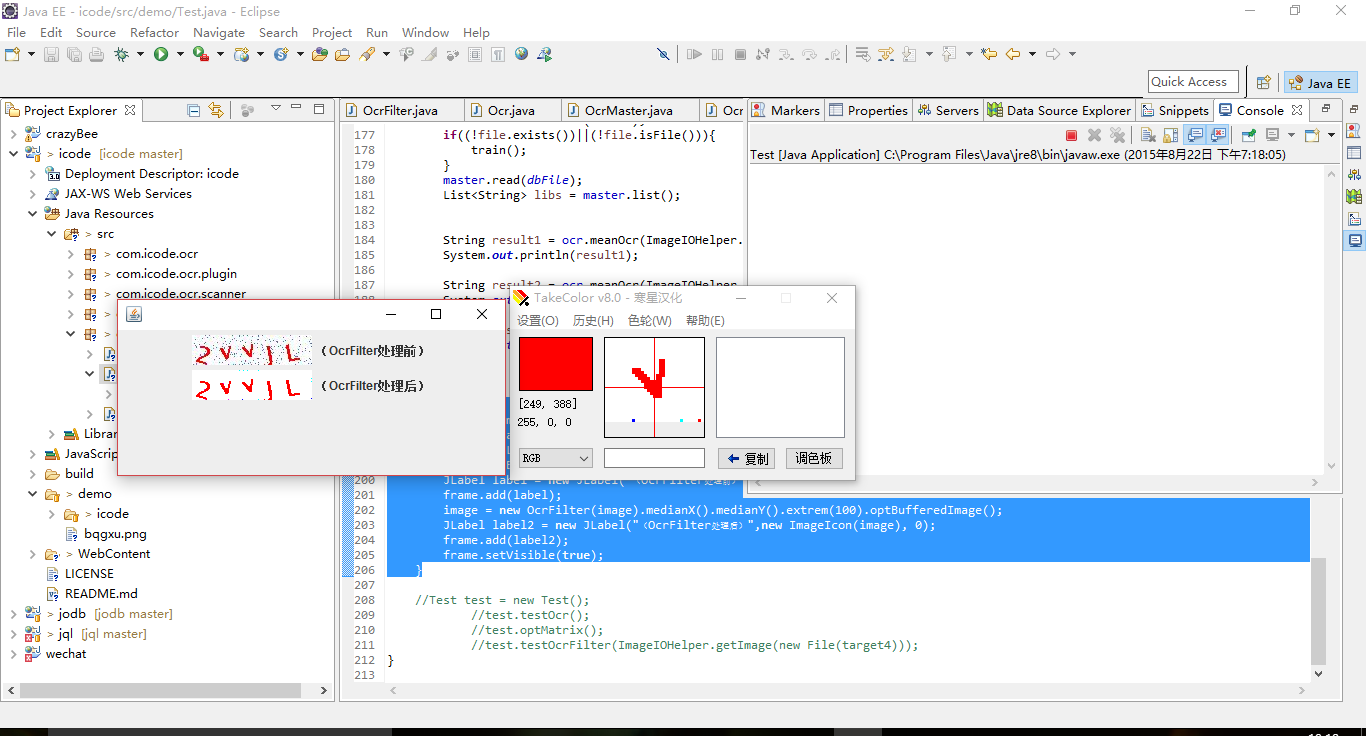
接下来我们可以只保留RGB=(255,0,0),把其他非RGB=(255,0,0)的部分涂成白色就OK了:
public static void main(String[] args) throws IOException {
BufferedImage image = ImageIOHelper.getImage(new File(target4));
JFrame frame = new JFrame();
frame.setLayout(new FlowLayout());
frame.setBounds(480, 240, 900, 600);
JLabel label = new JLabel("(OcrFilter处理前)",new ImageIcon(image), 0);
frame.add(label);
image = new OcrFilter(image).medianX().medianY().extrem(100).keepRGB(255, 0, 0).optBufferedImage();
JLabel label2 = new JLabel("(OcrFilter处理后)",new ImageIcon(image), 0);
frame.add(label2);
frame.setVisible(true);
}
}
处理后效果:
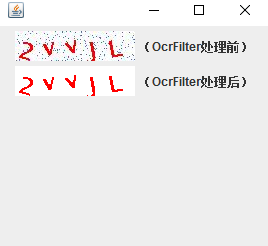
最后再来编码(程序中默认使用0和1)
protected boolean code(int[] pixels, int w, int h, int i) {
ColorModel cm = ColorModel.getRGBdefault();
int r = cm.getRed(pixels[i]);
int g = cm.getGreen(pixels[i]);
int b = cm.getBlue(pixels[i]);
if(r==255&&g==0&&b==0){
return true;
}else {
return false;
}
}
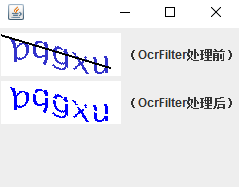
2.图像有干扰线,如![]() 。
。
如果干扰线颜色和字符颜色色差较大,package com.icode.ocr下的OcrFilter同样也有能力处理,方法是通过二值化后再将干扰色滤除。
public class MyIcodeRecognizer extends Ocr {
JFrame frame = new JFrame();
public MyIcodeRecognizer() {
frame.setLayout(new FlowLayout());
frame.setBounds(200, 200, 200, 200);
}
@Override
protected BufferedImage filter(BufferedImage image) {
JLabel label = new JLabel("(OcrFilter处理前)",new ImageIcon(image), 0);
frame.add(label);
//无噪点可不用中值滤波,增强颜色后过滤即可
image = new OcrFilter(image).extrem(100).keepRGB(0, 0, 255).optBufferedImage();
JLabel label2 = new JLabel("(OcrFilter处理后)",new ImageIcon(image), 0);
frame.add(label2);
frame.setVisible(true);
return image;
}
//该方法需与filter方法配合
@Override
protected boolean code(int[] pixels, int w, int h, int i) {
ColorModel cm = ColorModel.getRGBdefault();
int r = cm.getRed(pixels[i]);
int g = cm.getGreen(pixels[i]);
int b = cm.getBlue(pixels[i]);
if(r==0&&g==0&&b==255){
return true;
}else {
return false;
}
}
public static void main(String[] args) {
BufferedImage target = ImageIOHelper.getImage(new File("demo/bqgxu.png"));
MyIcodeRecognizer ocr = new MyIcodeRecognizer();
List codes = ocr.code(target);
int w = ocr.getStdWidth();
for(String code:codes){
for(int i=0;i<code.length()-w;i+=w){
System.out.println(code.substring(i, i+w));
}
System.out.println("\n");
}
}
}
效果如下:
二值编码输出:
00110000000000000000
00110000000000000000
00110000000000000000
00011000010000000000
00011000000000100000
00011001000000110000
00011000000000010000
00001100000000010000
00001100000000010000
00001100000000010000
00001100000000010000
00001100000000000000
00001100000000000000
00001100000000000000
00001100000001000000
00001110000100000000
00001100110000000000
00001100000000000000
00001100000000000000
00000011110000000000
00000110000001000000
00000100000001000000
00000000000001100000
00000000000001100000
00011000000000000000
00011000000000000000
00011000000000000000
00011000000001100000
00011000000001100000
00001100000001100000
00001100000001100000
00000110000111100000
00000001110001100000
00000000000001100000
00000000000001000000
00000000000001000000
00000000000001000000
00000000000010000000
00000111100000000000
00001100000000000000
00000100000001000000
00000000000001000000
00000000000001000000
00011000000000000000
00011000000000000000
00001000000000000000
00001000000001100000
00001000000001100000
00000100000001100000
00000010000001100000
00000001000001100000
00000000100001100000
00000000000001100000
00000000000001100000
00001000000000000000
00000011000000000000
00000000100110000000
00010000000000000000
00000000000000000000
00000000000000000000
00000000000000000000
00000000000000000000
00000000000000000000
00000000000000000000
00000001000000000000
00000000100100000000
00000000111000000000
00000001001000000000
00000000000100000000
00001000000100000000
00001000000100000000
00000000000010000000
00000000000010000000
00000000000001000000
00000000000001000000
00000000000000100000
00000000000011100000
00110000000011100000
00110000000001110000
00111000000001110000
00111000000001110000
00111000000001110000
00011000000001110000
00000000000001110000
00100000000001110000
00111000000001110000
00111000000000000000
00111000000000000000
00111000000011110000
00111000000011110000
00111000000111110000
00011100001101110000
00011111111101110000
00000111110000000000
00000000000000000000
前期需采集足够多的训练样本,通过人工训练生成如下的二值编码库,后期就可以基于该样本库来进行识别。 ...
b=
00110000000000000000
00110000000000000000
00110000000000000000
00011000010000000000
00011000000000100000
00011001000000110000
00011000000000010000
00001100000000010000
00001100000000010000
00001100000000010000
00001100000000010000
00001100000000000000
00001100000000000000
00001100000000000000
00001100000001000000
00001110000100000000
00001100110000000000
00001100000000000000
00001100000000000000
00000000000000000000
q=
00000011110000000000
00000110000001000000
00000100000001000000
00000000000001100000
00000000000001100000
00011000000000000000
00011000000000000000
00011000000000000000
00011000000001100000
00011000000001100000
00001100000001100000
00001100000001100000
00000110000111100000
00000001110001100000
00000000000001100000
00000000000001000000
00000000000001000000
00000000000001000000
00000000000010000000
00000000000000000000
g=
00000111100000000000
00001100000000000000
00000100000001000000
00000000000001000000
00000000000001000000
00011000000000000000
00011000000000000000
00001000000000000000
00001000000001100000
00001000000001100000
00000100000001100000
00000010000001100000
00000001000001100000
00000000100001100000
00000000000001100000
00000000000001100000
00001000000000000000
00000011000000000000
00000000100110000000
00000000000000000000
x=
00010000000000000000
00000000000000000000
00000000000000000000
00000000000000000000
00000000000000000000
00000000000000000000
00000000000000000000
00000001000000000000
00000000100100000000
00000000111000000000
00000001001000000000
00000000000100000000
00001000000100000000
00001000000100000000
00000000000010000000
00000000000010000000
00000000000001000000
00000000000001000000
00000000000000100000
00000000000000000000
u=
00000000000011100000
00110000000011100000
00110000000001110000
00111000000001110000
00111000000001110000
00111000000001110000
00011000000001110000
00000000000001110000
00100000000001110000
00111000000001110000
00111000000000000000
00111000000000000000
00111000000011110000
00111000000011110000
00111000000111110000
00011100001101110000
00011111111101110000
00000111110000000000
00000000000000000000
00000000000000000000
#【关键】最后的最后,两种方式——greedyOcr(贪婪)&meanOcr(吝啬)
greedyOcr
public final String greedyOcr(BufferedImage originalImage,List libs){
String result = "";
List codes = code(originalImage);
for(String code : codes){
int MaxCount = 0;
String target = "";
for(String lib : libs){
int count = 0;
for(int i=-DIFFERENCE;i<=DIFFERENCE;i++){
int tmp = 0;
int dif = Math.abs(i);
for(int j=0;j<code.length()-dif;j++){
if(i<0){
if(code.charAt(j+dif)=='1'&&lib.charAt(START_INDEX+j)=='1'){
tmp++;
}
}else if (i==0) {
if(code.charAt(j)=='1'&&lib.charAt(START_INDEX+j)=='1'){
tmp++;
}
}else {
if(lib.charAt(START_INDEX+dif+j)=='1'&&code.charAt(j)=='1'){
tmp++;
}
}
}
if(tmp>count){
count = tmp;
}
}
if(count>MaxCount){
MaxCount = count;
target = lib;
}
}
result+=target.charAt(0);
}
return result;
}
meanOcr
public final String meanOcr(BufferedImage originalImage,List libs){
String result = "";
List codes = code(originalImage);
for(String code : codes){
int MinCount = stdWidth*stdHeight;
String target = "";
for(String lib : libs){
int count = stdWidth*stdHeight;
for(int i=-DIFFERENCE;i<=DIFFERENCE;i++){
int tmp = 0;
int dif = Math.abs(i);
for(int j=0;j<code.length()-dif;j++){
if(i<0){
if(code.charAt(j+dif)!=lib.charAt(START_INDEX+j)){
tmp++;
}
}else if (i==0) {
if(code.charAt(j)!=lib.charAt(START_INDEX+j)){
tmp++;
}
}else {
if(lib.charAt(START_INDEX+dif+j)!=code.charAt(j)){
tmp++;
}
}
}
if(tmp<count){
count = tmp;
}
}
if(count<MinCount){
MinCount = count;
target = lib;
}
}
result+=target.charAt(0);
}
return result;
}
参数说明:
不同之处:

帮杰
疯狂于web和智能设备开发,专注人机互联。





HOW DO I DIY MY OWN REMOTE CONTROL SWITCH IN MY DORMITORY

THE SIMPLEST KALMAN FILTER IN THE WORLD

COMPUTING MEAN AND VARIANCE RECURSIVELY

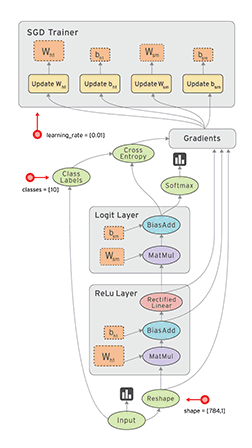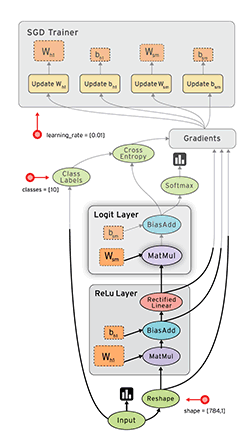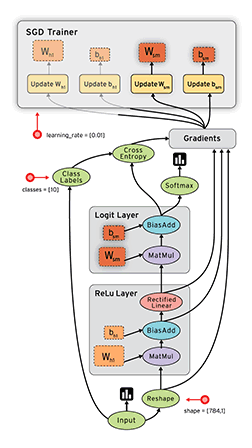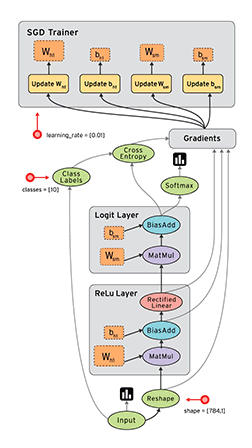
LEARNING GOOGLE TENSORFLOW [L1: MAKE THE FIRST ACUAINTANCE]

帮杰 2017-02-13
一种可能更好的匹配方法是贪婪型和吝啬型的加权